이날의 코드
https://horangcat.tistory.com/
220114) 머신러닝 첫날
권혜윤 강사님이 오셨고, 교재 두권을 받았다! (사실 이미 전자책으로 샀지만,, 실물 책 있으면 좋지..) - 핸즈온 머신러닝 http://aladin.kr/p/cNZoF 핸즈온 머신러닝 지능형 시스템을 구축하려면 반드
horangcat.tistory.com
데이터는 여기
https://www.kaggle.com/sdk1810/playtennis
PlayTennis
Play Tennis example from the book Machine Learning by Tom M. Mitchell
www.kaggle.com
전처리
# data 불러오기
pd.read_csv('playtennis.csv')
# 모두 숫자로 바꿔준다
tennis_data.outlook.replace("sunny",0, inplace=True)
tennis_data.outlook = tennis_data.outlook.replace("overcast", 1)
tennis_data.outlook = tennis_data.outlook.replace("rainy", 2)
tennis_data.temp.replace('hot', 1, inplace=True)
tennis_data.temp.replace('mild', 2, inplace=True)
tennis_data.temp.replace('cool', 3, inplace=True)
tennis_data.humidity.replace('high', 1, inplace=True)
tennis_data.humidity.replace('normal', 2, inplace=True)
tennis_data.windy = tennis_data.windy.replace(True, 1)
tennis_data.play.replace('no', 1, inplace=True)
tennis_data.play.replace('yes', 2, inplace=True)
# 독립변수와 종속변수를 분리해준다
X = tennis_data.loc[:,'outlook':'windy'] # 독립변수만 X에 저장
y = tennis_data['play'] # 종속변수만 y에 저장
모델 학습
from sklearn.tree import DecisionTreeClassifier
dt_clf = DecisionTreeClassifier() # Decision Tree 객체 생성
dt_clf.fit(X, y) # 데이터 학습
미래 예측
# 알고 싶은 미래의 데이터 넣어보기
future = pd.DataFrame( data={'outlook':0, 'temp':1, 'humidity':2, 'windy':1},
index=[0] ) future # sunny, hot, normal, windy한 날씨에 테니스를 칠 것인가?
dt_clf.predict(future) # 결과는 2로, play = yes. 칠 것이라는 예측.
모델 정확도 확인
from sklearn.metrics import accuracy_score
accuracy_score(y, dt_clf.predict(X)) # 1이 나온다. DT 정확도는 무조건 100%
Decision Tree 시각화
# 라이브러리 임포트
from sklearn import tree
from IPython.display import Image
import pydotplus
import os
# 트리 생성
dt_dot_data = tree.export_graphviz(dt_clf, out_file=None, feature_names=X.columns,
class_names=['Play_No','Play_Yes'],
filled=True, rounded=True,
special_characters=True)
# 그래프 그리기
dt_graph = pydotplus.graph_from_dot_data(dt_dot_data)
# 이미지 보기
Image(dt_graph.create_png()) # 지니=불순도. 지니지수 낮을수록 잘 분류된 것
시각화 결과

알아야 되는 것
Q1. 트리 해석하기






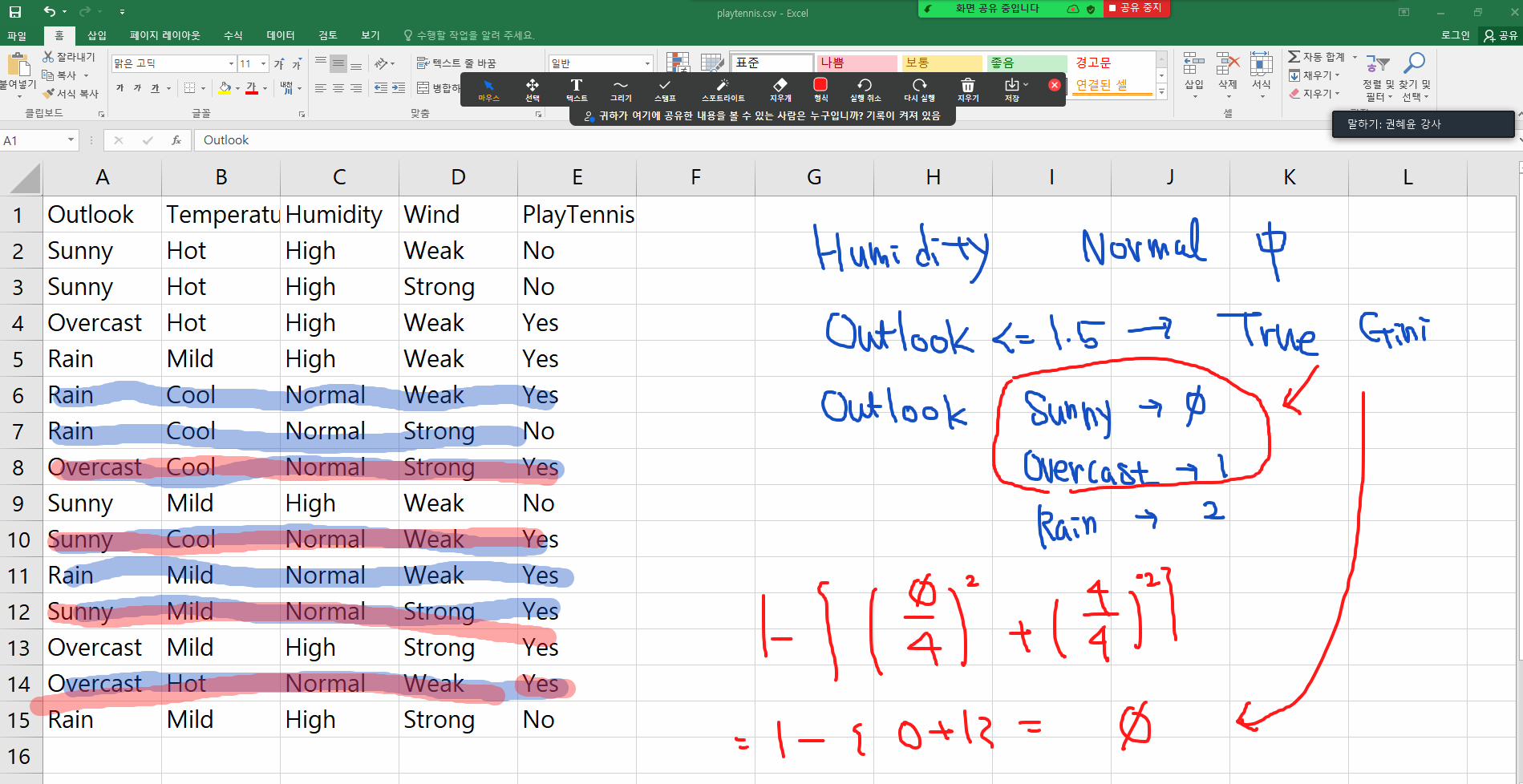
Q2. 결정 나무 정확도가 무조건 100%가 나오는 이유는?
- Tree 만든 데이터는 정확도 100%. 데이터 보고 Gini 계산해서 Tree 만듬.
- 모든 데이터로 만든 Tree가 정확한 Tree인지 부정확한 Tree인지 알 수 없음.
- 따라서 해야할 일!
1. 전체 데이터 중 일부는 Tree 만들고(75%) - Train Set
2. 일부는 Tree 안만들고 보관 - Test Set
- Tree 만들어지고 나서 2에서 보관한 데이터로 Tree가 얼마나 정확한지 측정
Q3. 지니 지수란 무엇인가?
- 불순도. 낮을수록 잘 분류된 것. 높을수록 데이터가 분산되어있다.

Q4. 모델의 파라미터를 조정한다면?
https://towardsdatascience.com/how-to-tune-a-decision-tree-f03721801680
How to tune a Decision Tree?
Hyperparameter tuning
towardsdatascience.com
train set과 test set 분리, 성능 평가(accuracy score)
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y)
dt_clf = DecisionTreeClassifier() # tree 만들 객체
dt_clf.fit(X_train, y_train) # tree를 만들었음
dt_clf.predict(X_test) # test data 예측
accuracy_score(y_test, dt_clf.predict(X_test)) # 찐, 예측 순서로 쓴다accuracy_score가 계속 바뀐다? - train set, test set이 고정되어 있지 않기 때문.
train set, test set 비율을 원하는대로 바꾸고, random_state 정해서 셋을 고정할 수 있다.
# train:test 비율 바꾸기 8:2
# random_state 정해주기(보통 세자리 씀)
train_test_split(X, y, test_size=0.2, random_state=777)
* 전체 노트북 파일은 git에 있습니다.
https://github.com/nojiyoon/SeSAC_code
GitHub - nojiyoon/SeSAC_code: 강의 code
강의 code. Contribute to nojiyoon/SeSAC_code development by creating an account on GitHub.
github.com
'Data Science' 카테고리의 다른 글
| Random Forest Classifier, 전에 몰랐던 것들 (0) | 2022.01.18 |
|---|---|
| 220117) Iris data로 Random Forest 실습 (0) | 2022.01.17 |
| 220114) 머신러닝 첫날 (0) | 2022.01.14 |
| 220113) AWS와 머신러닝 (0) | 2022.01.13 |
| 송길영 - 상상하지 말라 (0) | 2022.01.12 |